Table of Links
2 Approach
2.2 Multimodal Instruction Finetuning
2.3 Curriculum Learning with Parameter Efficient Finetuning
4 Results
4.1 Evaluation of SpeechVerse models
4.2 Generalization Across Instructions
4.3 Strategies for Improving Performance
6 Conclusion, Limitations, Ethics Statement, and References
A Appendix
A.1 Audio Encoder Pre-training
4.3 Strategies for Improving Performance
We further evaluate strategies to improve the multi-task model’s performance specially for unseen tasks and class labels. First, we leverage contrained decoding [40] for tasks that have a pre-defined set of finite outcomes. Next, we also study joint decoding of the output of the task with the ASR hypotheses of the audio for certain complex spoken language understanding tasks.
\ 4.3.1 Constrained Decoding
\ The work in [40] introduced a model-agnostic technique to enforce domain-specific knowledge and constraints during text generation. Building on this prior approach, we have explored applying decoding constraints to the SpeechVerse model to improve generalization to unseen speech classification tasks. Rather than allowing the model to generate freely in response to a prompt, the decoding is restricted to output from a predefined vocabulary of class names. For example, in an intent classification task, the model would be constrained to only generate intent labels such as “playradio”, “datetimequery” or “cooking_recipe”. By limiting the output space, the model is more likely to produce the desired class label rather than unrelated text.
\ We meticulously benchmark the model’s performance on close-ended tasks, such as a diverse set of classification tasks, that have a pre-defined set of finite class labels. To understand the influence of the instruction prompts, we divide this study into two parts: (1) where we only provide the class labels in the prompt, and (2) where we provide an accompanying description of each class label in the prompt. We ensure that none of these class labels were seen during training, and hence these are all novel tasks for the model. Further, we evaluate the efficacy of employing constrained decoding in each of these two parts, as the class labels are known to us beforehand. Note here that the SL task can be considered a harder task as the model has to correctly classify a slot label as well as identify the corresponding slot value from the speech. Hence, we report both, the SLU-F1 metric as well as the SD-F1 (Slot label Detection) metric for SL. The results of this study are presented in Table 7.
\ We observe that including descriptions in the prompt has inconsistent results, which can be attributed to the quality and subjectivity of the descriptions provided in the prompt, especially as these descriptions were not seen during training. However, we see that constrained decoding improves upon the results in all cases, and most significant gains are observed only when descriptions are provided with constrained decoding. This indicates that providing descriptions indeed steers the model towards better comprehension of the task semantics, but only constrained decoding is able to objectively prune the noise introduced by any prompt bias. This phenomena is further revealed in the SL task, where the SLU-F1 has a lower absolute value compared to SD-F1, as the SLU-F1 metric incorporates both slot label and slot value, whereas constrained decoding can only be applied to the slot label (hence the higher SD-F1). Similarly, for a completely unseen task of Domain Classification (DC), where the goal is to classify the content of the audio into five domains like healthcare, technology etc, we observe a strong performance of 62% accuracy with constrained decoding.
\ 4.3.2 Joint Decoding
\ Certain SLU tasks require the model to understand the semantics of the audio or perform a operation on the content of the audio. For example, KWE task is about extracting important keywords from the ASR hypothesis of the audio. Since this is a multi-step reasoning process for the model, we take inspiration from the existing work [41] on Chain-of-Thought (CoT) prompting. We train our model to first decode the ASR hypothesis of the audio, followed by the output of the task. The prompts used for the joint elicitation of ASR hypothesis and the task output are described in the Table 8. For a representative set of SLU tasks including IC, KWE and ER, we re-train the Task-FT models by adding a small portion of such multi-step examples along with single-task examples. We compare the results with and without joint decoding with ASR hypothesis in the Table 9.
\ 
\ 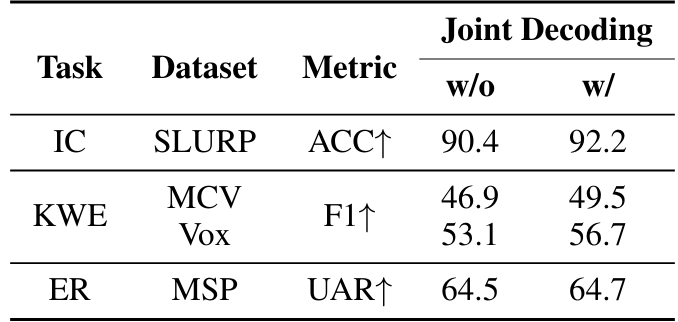
\ The results in the table showcase that augmenting the training data with compound goals helps to improve the performance for all three tasks. The improved performance can be attributed to the possibility of self-attention on the already decoded ASR hypothesis in the decoder of our multimodal model. Further, such multi-step training examples brings out the true multimodal capabilities of the model to successfully complete the combination of tasks. Further, such a paradigm can help save crucial inference latency by using a single call of the large multi-modal model for obtaining both the transcript and the task output. A more detailed analysis on understanding the benefits of joint decoding will be conducted in future work.
\
:::info Authors:
(1) Nilaksh Das, AWS AI Labs, Amazon and Equal Contributions;
(2) Saket Dingliwal, AWS AI Labs, Amazon(skdin@amazon.com);
(3) Srikanth Ronanki, AWS AI Labs, Amazon;
(4) Rohit Paturi, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Jie Yuan, AWS AI Labs, Amazon;
(8) Dhanush Bekal, AWS AI Labs, Amazon;
(9) Xing Niu, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Karel Mundnich, AWS AI Labs, Amazon;
(13) Monica Sunkara, AWS AI Labs, Amazon;
(14) Daniel Garcia-Romero, AWS AI Labs, Amazon;
(15) Kyu J. Han, AWS AI Labs, Amazon;
(16) Katrin Kirchhoff, AWS AI Labs, Amazon.
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
Tidak ada komentar:
Posting Komentar